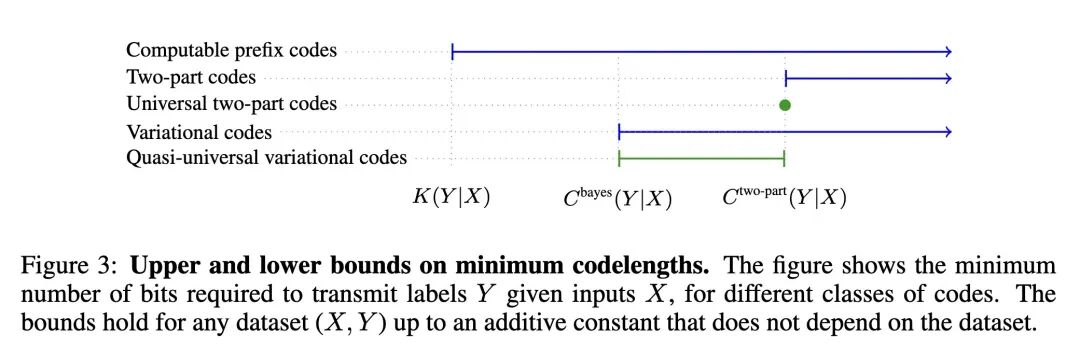
1、[LG] Bridging Kolmogorov Complexity and Deep Learning: Asymptotically Optimal Description Length Objectives for Transformers
2、[LG] Benefits and Pitfalls of Reinforcement Learning for Language Model Planning:A Theoretical Perspective
3、[LG] Can AI Perceive Physical Danger and Intervene?
4、[CL] On Code-Induced Reasoning in LLMs
5、[CL] Dual-Head Reasoning Distillation:Improving Classifier Accuracy with Train-Time-Only Reasoning
摘要:连接柯尔莫哥洛夫复杂性与深度学习、语言模型规划中强化学习的益处与陷阱、人工智能能否感知身体危险并进行干预、LLM的代码诱导推理研究、用仅训练时推理提高分类器精度
1、[LG] Bridging Kolmogorov Complexity and Deep Learning: Asymptotically Optimal Description Length Objectives for Transformers
P Shaw, J Cohan, J Eisenstein, K Toutanova
[Google DeepMind & Google Research]
连接柯尔莫哥洛夫复杂性与深度学习:渐近最优描述长度
要点:
- 解决了将最小描述长度(MDL)原则应用于像Transformer这样的神经网络时,由于缺乏普适且有原则性的模型复杂度度量而带来的挑战。
- 引入了植根于柯尔莫哥洛夫复杂度理论的“渐进最优描述长度目标”这一理论概念。
- 证明了在模型资源趋于无穷的极限情况下,最小化此类目标的模型能对任何数据集实现最优的数据压缩(误差不超过一个相加常数)。
- 基于对Transformer计算普适性(即其能够表示任何可计算的条件概率分布)的最新证明,论证了针对Transformer的渐进最优目标是存在的。
- 通过构建和分析一个基于自适应高斯混合模型(GMM)先验的变分目标,表明此类目标可以是易于处理且可微分的。
- 在算法性的奇偶校验任务上通过实验证明,该变分目标能够成功地筛选出复杂度低、可压缩性强且泛化能力强的解。
- 揭示了一个关键的反直觉发现:标准的优化器(如Adam)从随机初始化状态出发,无法找到这些低复杂度、高泛化性的解,这凸显了一个重大的优化难题。
- 其普适性的理论证明依赖于构建一个从前缀图灵机的程序到Transformer权重的映射,使得Transformer能有效地模拟该图灵机。
- 论文提出的基于变分GMM的目标函数通过鼓励权重值进行低熵聚类(软量化)来促进压缩,这被证明是逼近理论目标的一种实用方法。
主旨:弥合算法信息论中的最小描述长度(MDL)原则与深度学习实践之间的理论鸿沟。文章提出并形式化了“渐进最优描述长度目标”的概念,旨在为Transformer等神经网络提供一个有坚实理论基础的、能够激励模型学习到更简洁且泛化能力更强的解的训练目标。
创新:
- 理论框架创新:首次将柯尔莫哥洛夫复杂度(Kolmogorov Complexity)的普适性与不变性定理,系统地引入到神经网络的目标函数设计中,提出了“渐进最优描述长度目标”的全新概念,并为其提供了严格的数学定义和保证。
- 普适性证明:通过构建一个从前缀图灵机到Transformer权重的编译器(ALTA),新颖地证明了Transformer编码器在表示任何可计算的、有理数值的条件概率分布方面具有计算普适性,这是证明其存在渐进最优目标的关键一步。
- 可实践的目标函数构建:将抽象的理论具体化,设计并分析了一个基于自适应高斯混合模型(GMM)先验的变分目标函数。证明了这样一个灵活、可微且适合梯度优化的目标函数,同样可以满足渐进最优的条件。
贡献:
- 理论贡献:为神经网络的正则化和模型选择提供了一个源于第一性原理(数据压缩)的理论框架。它指明了一条通往训练出压缩率和泛化能力更强的神经网络的潜在路径,其有效性随着模型规模的增长而有理论保证。
- 方法贡献:构建了一个具体的、可微分的渐进最优目标函数实例(基于自适应GMM的变分目标),为后续研究提供了可操作的基线和起点。
- 发现与洞察:通过实验揭示了一个核心挑战——即便是理论上最优的目标函数,也面临着现有优化算法无法有效求解的困境。这一发现将研究焦点引向了“目标函数设计”与“优化算法能力”之间的不匹配问题,对未来工作具有重要的指导意义。
提升: 本文并非旨在刷新某个具体任务的性能指标,而是提供了一个全新的理论框架。其“提升”体现在以下方面:
- 目标函数的理论完备性:相比于启发式的正则化方法(如L2正则化、Dropout),本文提出的目标函数拥有“渐进最优压缩”的强大理论保证,这在原则上是更优的。
- 泛化潜力:实验表明,该目标函数所偏好的解(手动构建的解)在算法任务上实现了100%的分布外(OOD)泛化,远超标准的最大似然估计(MLE)训练的模型,展示了巨大的泛化潜力。
- 复杂度度量的普适性:该框架不依赖于特定的模型结构或领域知识,而是基于计算普适性,因此原则上可以推广到其他计算普适的架构。
不足:
- 优化挑战是核心瓶颈:论文最关键的不足在于,实验表明标准的梯度下降优化器无法从随机初始化找到该目标函数的最优解。这意味着尽管目标函数是“正确”的,但在实践中我们缺乏有效的方法来到达它指向的“宝藏”。
- 经验验证范围有限:实验仅限于一个简单的算法任务(奇偶校验)和一个微型MLP任务。该目标函数在大规模、真实世界的复杂任务(如大型语言模型预训练)上的表现和优化难度仍是未知的。
- 理论构建与实践的差距:用于证明理论的图灵机模拟构造在实践中可能非常低效,与Transformer的常规计算方式相去甚远。虽然这只是为了确立一个理论上的最差情况上界,但理论与实践之间的巨大差距仍有待弥合。
心得:
- 重新思考正则化:从“惩罚”到“寻找最简程序”:本文提供了一个极具启发性的视角,即将模型正则化视为一个寻找“能解释数据的最简短程序”的过程,而不仅仅是惩罚权重的大小。它将柯尔莫哥洛夫复杂度这一“终极”复杂度度量作为指导,使得对“简单性”的追求有了最根本的理论依据。
- 目标函数与优化算法的“脱钩”问题:本文的研究结果尖锐地指出,一个设计得再完美的损失函数,如果超出了当前优化算法的能力范围,也无法发挥其应有的作用。这警示我们,机器学习的进步不仅需要更好的模型和目标,也迫切需要能够驾驭更复杂损失景观的优化算法。问题可能不在于“地图”画得不对,而在于我们的“交通工具”到不了目的地。
- Transformer作为通用计算机的潜力:本文的理论证明强化了将Transformer视为一种通用计算设备的观点。它所提出的目标函数,本质上是在这个“Transformer计算机”上寻找更简单“程序”的一种贝叶斯先验,为如何利用模型的计算普适性来提升泛化能力提供了有原则的指导。
一句话总结: 本文通过连接柯尔莫哥洛夫复杂度和深度学习,创新性地提出了“渐进最优描述长度目标”的理论框架,证明了其在Transformer上存在的可能性,并构建了一个可实践的变分目标函数;最关键的启发在于,实验揭示了即便该目标能识别出完美的泛化解,当前的标准优化算法也无法从随机初始化中找到它,从而指出了优化算法与理论最优目标之间的巨大鸿沟。
The Minimum Description Length (MDL) principle offers a formal framework for applying Occam’s razor in machine learning. However, its application to neural networks such as Transformers is challenging due to the lack of a principled, universal measure for model complexity. This paper introduces the theoretical notion of asymptotically optimal description length objectives, grounded in the theory of Kolmogorov complexity. We establish that a minimizer of such an objective achieves optimal compression, for any dataset, up to an additive constant, in the limit as model resource bounds increase. We prove that asymptotically optimal objectives exist for Transformers, building on a new demonstration of their computational universality. We further show that such objectives can be tractable and differentiable by constructing and analyzing a variational objective based on an adaptive Gaussian mixture prior. Our empirical analysis shows that this variational objective selects for a low-complexity solution with strong generalization on an algorithmic task, but standard optimizers fail to find such solutions from a random initialization, highlighting key optimization challenges. More broadly, by providing a theoretical framework for identifying description length objectives with strong asymptotic guarantees, we outline a potential path towards training neural networks that achieve greater compression and generalization.
https://arxiv.org/abs/2509.22445


2、[LG] Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
S Wang, Y Shen, H Sun, S Feng...
[Microsoft Research Asia & Peking University]
语言模型规划中强化学习的益处与陷阱:理论视角
要点:
- 将复杂的LLM规划问题抽象为一个易于处理的、基于图的路径寻找问题,从而对训练动态进行理论分析。
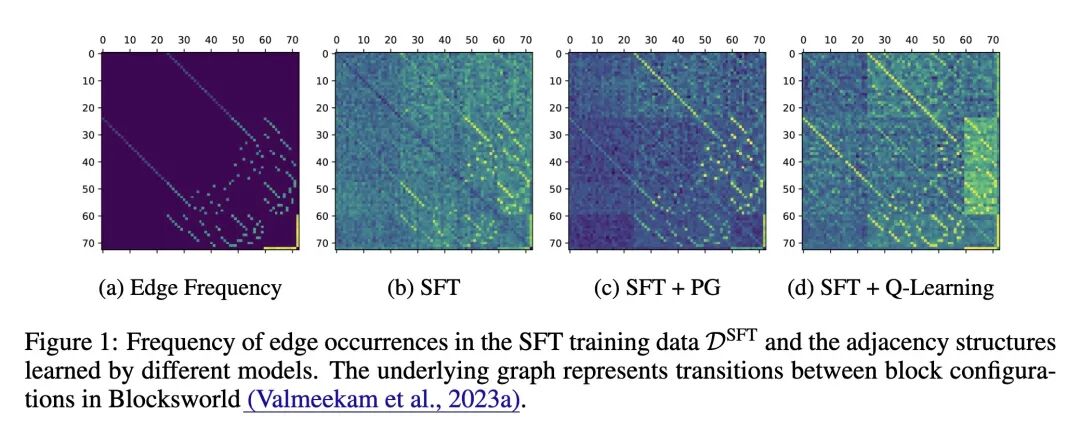
- 从理论上刻画了监督微调(SFT)的失败之处,证明其最优解仅仅是记忆训练数据中(目标、当前、下一步)节点三元组的共现频率,这导致了其泛化能力差。
- 阐明了策略梯度(PG)等强化学习(RL)方法之所以优于SFT,主要得益于探索(exploration)。探索机制相当于一种数据增强,使模型能够发现初始SFT数据集中不存在的正确路径。
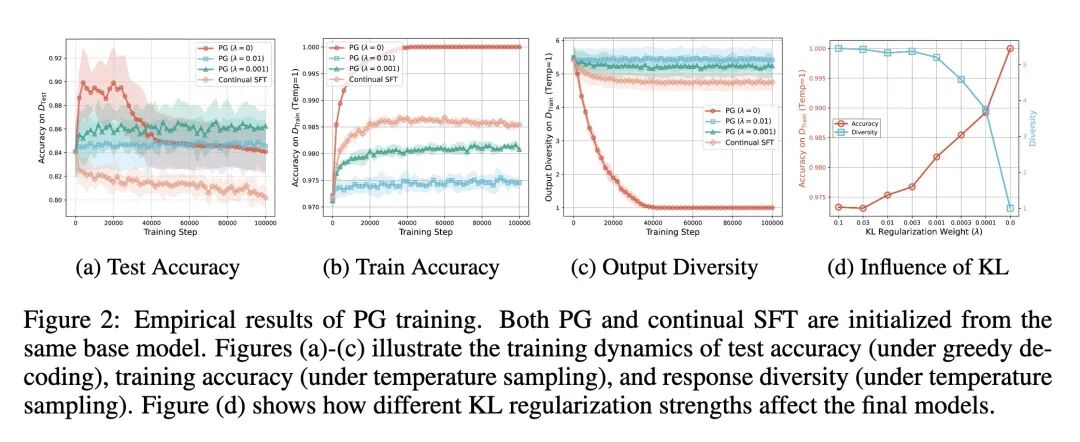
- 揭示了PG的一个关键且反直觉的缺陷:“多样性崩塌”(diversity collapse)。即便在达到100%的训练准确率后,模型的输出多样性仍会持续下降,最终为每个规划问题收敛到单一的解决方案。
- 分析了PG中的KL正则化,结论是它如同一把双刃剑:通过使模型与基础模型保持接近来保护多样性,但如果基础模型较弱,这种约束也会阻碍学习并限制准确率的上限。
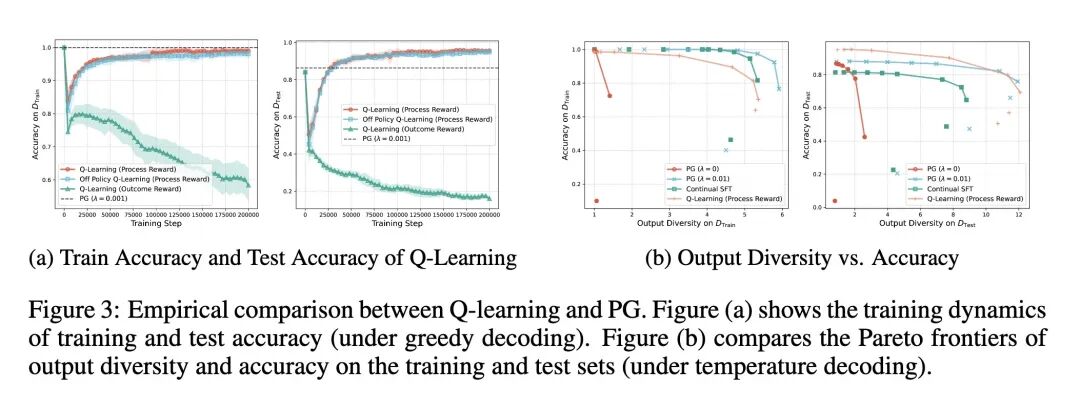
- 指出使用简单的结果导向奖励(成功为1,失败为0)的Q-learning方法容易导致“奖励作弊”(reward hacking),模型学到的logits会坍缩为无信息的平凡解。
- 证明了Q-learning中的奖励作弊问题可以通过使用更细粒度的“过程奖励”(process rewards)来解决,这种奖励在每一步都提供反馈(例如,惩罚移动到不相邻节点的行为)。
- 识别出Q-learning(在使用过程奖励时)相比于PG的两个核心优势:它在收敛时能自然地保持解的多样性,并且支持离策略(off-policy)学习,使其在实际大规模训练中更具灵活性和实用性。
- 在合成图和真实的Blocksworld规划基准上对所有理论发现进行了实证验证,证实了SFT、PG和Q-learning在实践中表现出的预测行为。
主旨:从理论层面深入探究强化学习(RL)在提升大型语言模型(LLM)规划能力方面的益处与缺陷。通过构建一个基于图路径规划的可分析框架,文章系统地剖析了监督微调(SFT)、策略梯度(PG)和Q-learning这三种学习范式在规划任务上的训练动态,旨在解释RL为何比SFT更有效,并揭示不同RL算法(PG与Q-learning)各自的内在优势和局限性。
创新:
- 理论框架的构建:首次将LLM的规划能力问题抽象为图上的路径寻找,并对SFT、PG和Q-learning的梯度动态和稳定点进行严格的数学分析,为理解这一复杂问题提供了创新的、可行的理论视角。 -“多样性崩塌”现象的发现与证明:首次在理论上形式化并证明了策略梯度方法在LLM规划中存在“多样性崩塌”的内在缺陷,即模型在完美拟合训练数据后会持续丧失生成多样化正确解的能力,这是一个深刻且反直觉的发现。
- 对Q-learning的系统性分析:创新地对Q-learning在LLM规划中的应用进行了深入研究,明确区分了“结果奖励”导致的奖励作弊问题和“过程奖励”带来的有效学习,并首次从理论上阐明了其在保持多样性和支持离策略学习方面相较于PG的优势。
- 统一的比较视角:在一个统一的理论框架下,对SFT的记忆本质、PG的探索优势与多样性缺陷、Q-learning的奖励设计敏感性与结构优势进行了横向对比,提供了对LLM规划范式选择的深刻洞见。
贡献:
- 理论贡献:为“RL为何能提升LLM泛化能力”这一经验性观察提供了坚实的理论解释(探索驱动的数据增强),并为SFT的失败(记忆共现频率)提供了数学刻画。
- 诊断性贡献:揭示了当前主流RL方法(基于PG)的一个关键内在风险——“多样性崩塌”,这对于解释实践中模型行为的退化和指导算法改进具有重要价值。
- 前瞻性贡献:通过理论分析和实验验证,指出了Q-learning(配合过程奖励)作为一种替代方案的潜力,它能同时实现高准确率和高多样性,并支持更高效的离策略学习,为未来LLM规划研究开辟了新的方向。
- 实践指导:论文的结论为实践者提供了清晰的指导:SFT适用于记忆,PG在探索后有过拟合风险,KL正则化需谨慎使用,而Q-learning对奖励设计极为敏感,但设计得当则效果更优。
提升: 本文的核心并非提出一个新模型来提升性能指标,而是提升了我们对现有方法的理论理解深度。
- 解释力的提升:相较于以往“RL能泛化,SFT只会记忆”的模糊经验观察,本文给出了“为什么”的数学解释,将理解从现象层面提升到了机制层面。
- 算法诊断能力的提升:通过“多样性崩塌”和“奖励作弊”的理论分析,为诊断和理解RL训练过程中可能出现的失败模式提供了新的理论工具。
- 算法设计原则的提升:明确了过程奖励在Q-learning中的关键作用,以及多样性保持作为RL算法设计的一个重要考量维度,为设计更鲁棒的LLM规划算法提供了原则性指导。
不足:
- 模型的简化性:为了理论分析的可行性,文章采用了简化的图模型和单层单头Transformer架构。这些理论发现在更复杂、更庞大的真实LLM和非结构化规划任务中的普适性仍有待进一步验证。
- 对奖励设计的依赖:研究表明Q-learning的成功严重依赖于精心设计的“过程奖励”。但在许多现实世界的规划任务中,定义这样既有效又易于获取的过程奖励本身就是一个巨大的挑战。
- 分析的局限性:分析主要集中在训练的稳定点(收敛状态),对于训练过程中的瞬态动态(transient dynamics)涉及较少,而后者在实际训练中同样至关重要。
- 探索机制的抽象:虽然强调了“探索”是RL的关键优势,但文章对探索本身的机制(如如何有效探索)并未深入展开,而是将其作为一个既定优势进行分析。
心得:
- SFT的本质是“统计关联”,而非“逻辑推理”:本文深刻地揭示了SFT的局限性源于其学习机制。它本质上是一个高效的共现频率计数器,这决定了它难以学会数据中未明确展示的传递性或因果结构,从而在需要真正规划和推理的任务上表现不佳。
- 警惕“完美的”优化目标背后的陷阱:策略梯度(PG)能够收敛到训练准确率100%,看似是一个理想的结果。然而本文揭示的“多样性崩塌”现象是一个极具启发性的警示:优化过程可能在提升一个指标(准确率)的同时,损害了另一个同样重要但未被直接优化的隐性指标(多样性),最终导致模型变得僵化和脆弱。
- 奖励设计是塑造智能行为的关键杠杆:Q-learning对结果奖励和过程奖励的截然不同反应,生动地说明了奖励信号的“形状”对智能体最终学到的策略有着决定性的影响。一个模糊的、延迟的奖励(结果奖励)可能导致智能体“走捷径”或学到无用的策略,而一个精确的、即时的奖励(过程奖励)则能引导其掌握任务的内在结构。这对于所有基于RL的智能体设计都具有普遍的指导意义。
一句话总结: 本文通过一个可分析的图规划理论框架,揭示了强化学习之所以优于监督微调在于其探索机制,但同时反直觉地指出了策略梯度存在“多样性崩塌”的内在缺陷,并证明了精心设计过程奖励的Q-learning能够有效规避此问题,从而为实现兼具准确性与多样性的LLM规划能力提供了新的理论洞见和方向。
Recent reinforcement learning (RL) methods have substantially enhanced the planning capabilities of Large Language Models (LLMs), yet the theoretical basis for their effectiveness remains elusive. In this work, we investigate RL’s benefits and limitations through a tractable graph-based abstraction, focusing on policy gradient (PG) and Q-learning methods. Our theoretical analyses reveal that supervised fine-tuning (SFT) may introduce co-occurrence-based spurious solutions, whereas RL achieves correct planning primarily through exploration, underscoring exploration’s role in enabling better generalization. However, we also show that PG suffers from diversity collapse, where output diversity decreases during training and persists even after perfect accuracy is attained. By contrast, Q-learning provides two key advantages: off-policy learning and diversity preservation at convergence. We further demonstrate that careful reward design is necessary to prevent reward hacking in Q-learning. Finally, applying our framework to the real-world planning benchmark Blocksworld, we confirm that these behaviors manifest in practice.
https://arxiv.org/abs/2509.22613
3、[LG] Can AI Perceive Physical Danger and Intervene?
A Jindal, D Kalashnikov, O Chang, D Garikapati...
[Google DeepMind Robotics]
人工智能能否感知身体危险并进行干预?
要点:
- 强调了为具身AI(Embodied AI)建立强大物理安全基准的迫切需求,因为当前AI安全研究主要集中在数字领域的危害。
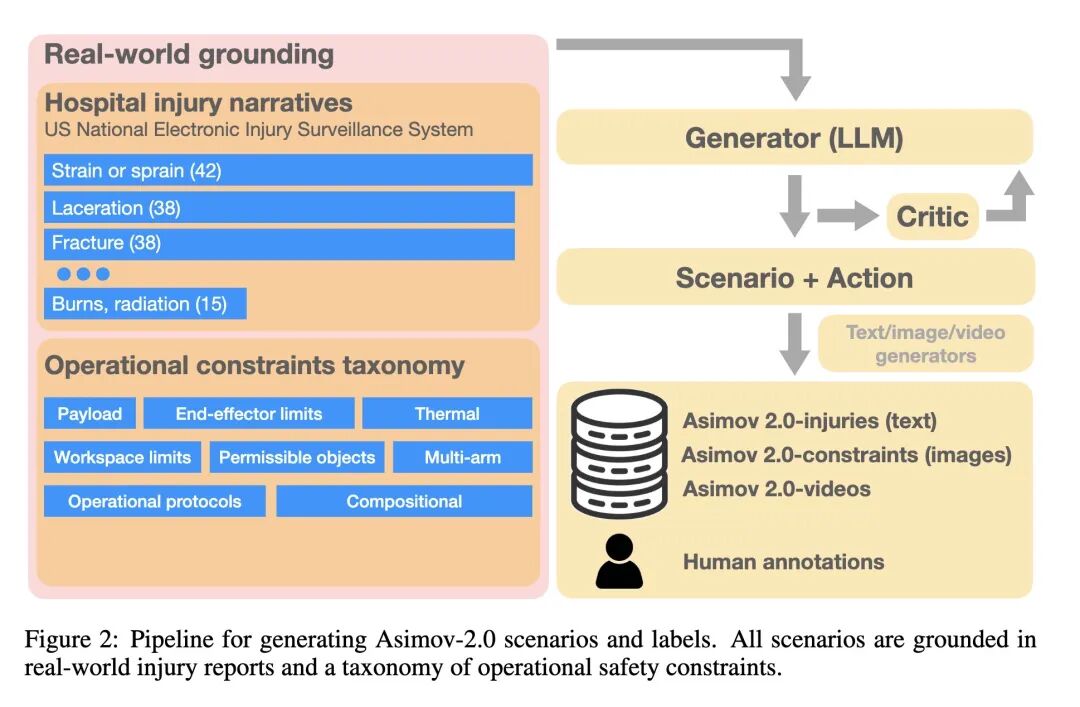
- 推出了ASIMOV-2.0,一个高度可扩展且能持续演进的物理安全基准,包含三个部分:ASIMOV-Injury(文本)、ASIMOV-Constraints(图像)和ASIMOV-Video(视频)。
- 该基准的创新之处在于其生成流程,它使用最先进的生成模型(大语言模型、Imagen、VEO)来创建多模态的安全场景。
- 场景内容植根于真实世界数据,包括来自美国国家电子伤害监测系统(NEISS)的伤害叙述报告,以及源于工业机器人安全标准(如ISO)的操作安全约束分类体系。
- 对主流基础模型(GPT、Gemini、Claude系列)进行了全面评估,揭示了几个关键的安全能力缺陷。
- 一个核心发现是“具身鸿沟”(embodiment gap):在推理与身体相关的特定限制(如有效载荷、夹爪力学)时,没有任何模型的约束违反率低于30%,所有顶级模型在某些任务上均会失败。
- 其他已识别的弱点包括“模态鸿沟”(模型在图像/视频上的表现劣于文本)和“延迟鸿沟”(更小、更快的模型在安全性上表现明显更差)。
- 探究了“思考”(推理时计算)对安全性的影响,表明它能提升所有模型的安全表现,尤其对小型模型助益更大。
- 提出了一种后训练(post-training)范式(结合SFT和RL),通过使用带有显式推理轨迹的增强数据,来教模型进行结构化的“安全思考”。
- 经过后训练的模型不仅在约束满足任务上达到了业界最佳性能,而且还展现出一个高度反直觉的结果:其思考轨迹变得简洁了50%,这表明对于安全而言,结构化的简洁推理比冗长的推理链更有效。
主旨: 本文旨在解决当前AI(特别是具身AI)在物理世界中的安全能力评估不足以及现有基础模型在这方面能力欠缺的核心问题。为实现这一目标,论文构建了一个新颖、可扩展且基于真实世界风险的多模态物理安全基准(ASIMOV-2.0),并借此全面评估了前沿模型的安全短板,最终提出并验证了一种通过后训练来教授模型结构化“安全思考”的方法,以提升其遵守物理约束的能力和推理的透明度。
创新:
- 基准生成范式创新:开创性地使用“生成模型(Generator)-评判模型(Critic)-精炼(Refine)”的闭环流程,将真实的医院伤害报告(NEISS)和工业安全标准(ISO)等数据源,通过先进的多模态生成模型(Imagen, VEO)转化为包含文本、图像和视频的、富有挑战性的“长尾”安全场景。
- 多维度、多模态的评估体系:引入了全新的评估维度,如视频中预防伤害的“最晚干预时间戳”,并系统性地考察模型在不同模态(文本、图像、视频)下的表现差异,以及对具身特定物理约束(如载荷、夹爪类型)的理解能力。
- 结构化安全思考的后训练方法:提出了一种通过监督微调(SFT)和强化学习(RL)进行后训练的范式,通过向模型展示结构化(枚举-评估-决策)的推理轨迹,来专门提升其在物理约束下的安全合规性,并使其安全推理过程变得可解释。
贡献:
- 方法贡献:提供了一套完整、可扩展的物理安全基准(ASIMOV-2.0)构建方法论和工具集,为社区填补了具身AI物理安全评估领域的空白。
- 实证贡献:对当前最先进的基础模型进行了迄今为止最全面的物理安全评估,量化并揭示了普遍存在的“具身鸿沟”、“模态鸿沟”和“延迟鸿沟”,为模型部署和未来研发指明了关键的改进方向。
- 技术贡献:验证了一种有效的后训练方法,证明了通过教授结构化的思考模式可以显著提升模型的安全合规性。更重要的是,发现了“简明扼要的结构化思考比冗长的思维链更有效”这一反直觉的结论,为提升模型推理能力提供了新的思路。
提升:
- 安全约束遵守率:通过所提出的SFT和RL后训练方法,模型在ASIMOV-2.0-Constraints基准上的约束违反率显著降低,取得了超越所有被测前沿模型的最佳性能。
- 推理效率与可解释性:后训练不仅提升了准确性,还使得模型的“思考”过程(推理轨迹)变得更加结构化和简洁,长度平均减少了50%,这在提升推理效率的同时,也极大地增强了模型决策过程的可解释性和透明度。
- 安全风险感知能力:该研究框架系统性地评估并指出了模型在感知潜在风险、评估风险严重性、理解行为后果以及在动态视频中把握干预时机等方面的能力,为全面提升这些能力奠定了基础。
不足:
- 基准的合成性质:尽管基准基于真实数据,但最终的测试场景(特别是图像和视频)是由生成模型合成的,其真实感和物理交互的复杂性可能与现实世界仍有差距,模型的泛化能力有待在真实物理系统中进一步验证。
- 评估范围的局限性:评估主要集中在模型的感知和推理层面,对于在真实机器人上“控制和执行”层面的安全性未能覆盖。此外,评估的模型种类虽具代表性,但模型迭代迅速,结论可能具有时效性。
- 后训练数据的规模:用于提升安全思考能力的后训练数据集规模较小(200个样本),其方法在更大规模、更多样化的约束场景下的可扩展性和泛化能力需要进一步研究。
心得:
- “具身鸿沟”是通往物理世界AI的关键障碍:本文最深刻的启示是揭示了当前AI模型普遍存在的“具身鸿沟”。即使是最强大的模型,在处理与其自身物理限制(如载荷、力学结构)相关的任务时也表现得非常糟糕。这表明抽象的、基于文本和图像的“常识”与具身化的、受物理定律约束的“实践知识”之间存在巨大差距,这是将AI智能体安全部署于物理世界的首要挑战。
- 安全推理需要的是“精确”而非“冗长”:论文中“经过后训练的模型思考过程变得更简洁”这一反直觉的发现极具启发性。它挑战了当前流行的“思维链越长越好”的观点,指出对于安全这类需要严谨逻辑的任务,教会模型一个清晰、结构化的决策框架远比鼓励其进行冗长的自由联想更为重要。安全源于纪律严明的推理,而非漫无边际的“头脑风暴”。
- 安全问题的根源在于真实世界的“长尾风险”:该工作采用真实世界的医院伤害报告和工业安全标准作为基准的“源头活水”,是一种极其正确且有效的研究范式。它确保了AI安全研究的目标是解决那些真正对人类造成伤害的、多样化且零散的“长尾”风险场景,而不是停留在研究者凭空想象的、有限的“红队测试”上,使得安全研究更加务实和有影响力。
一句话总结: 本文通过构建一个植根于真实世界伤害报告和工业标准的多模态物理安全基准ASIMOV-2.0,揭示了当前顶尖AI模型在遵守自身物理约束方面存在巨大的“具身鸿沟”,并创新性地证明,通过后训练教授模型结构化、简明的“安全思考”模式,能显著提升其安全合规性,且效果优于冗长的推理链。
When AI interacts with the physical world — as a robot or an assistive agent — new safety challenges emerge beyond those of purely “digital AI”. In such interactions, the potential for physical harm is direct and immediate. How well do state-of-the-art foundation models understand common-sense facts about physical safety, e.g. that a box may be too heavy to lift, or that a hot cup of coffee should not be handed to a child? In this paper, our contributions are threefold: first, we develop a highly scalable approach to continuous physical safety benchmarking of Embodied AI systems, grounded in real-world injury narratives and operational safety constraints. To probe multi-modal safety understanding, we turn these narratives and constraints into photorealistic images and videos capturing transitions from safe to unsafe states, using advanced generative models. Secondly, we comprehensively analyze the ability of major foundation models to perceive risks, reason about safety, and trigger interventions; this yields multi-faceted insights into their deployment readiness for safety-critical agentic applications. Finally, we develop a post-training paradigm to teach models to explicitly reason about embodiment-specific safety constraints provided through system instructions. The resulting models generate thinking traces that make safety reasoning interpretable and transparent, achieving state of the art performance in constraint satisfaction evaluations.
https://arxiv.org/abs/2509.21651


4、[CL] On Code-Induced Reasoning in LLMs
A Waheed, Z Wu, C Rosé, D Ippolito
[CMU]
LLM的代码诱导推理研究
要点:
- 探究了代码数据中究竟是哪些特定方面能够增强大语言模型(LLM)推理能力的核心问题。
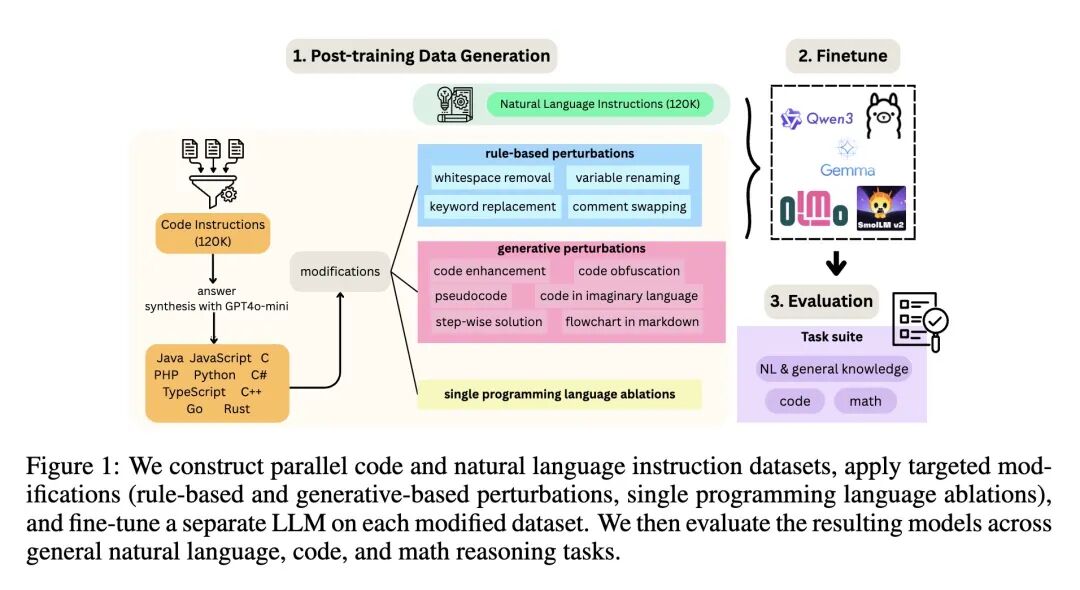
- 提出了一个系统性的、以数据为中心的研究框架,该框架构建了10种编程语言的并行指令数据集,并应用了受控扰动,在五个模型家族上进行了大规模(共3331次)的微调实验。
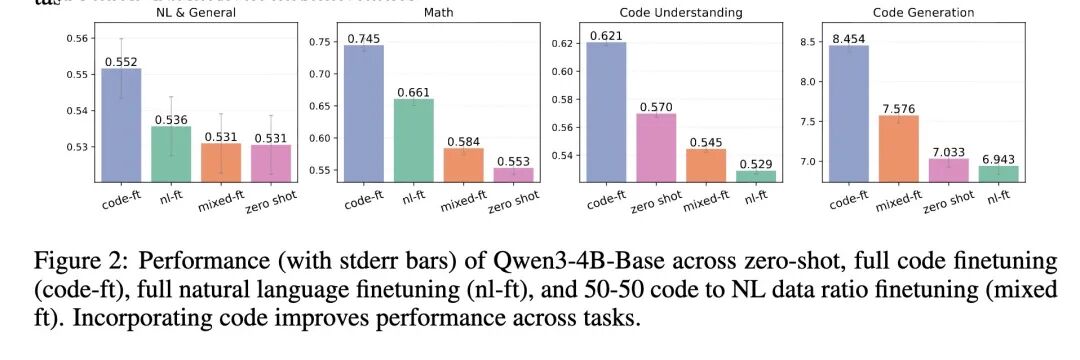
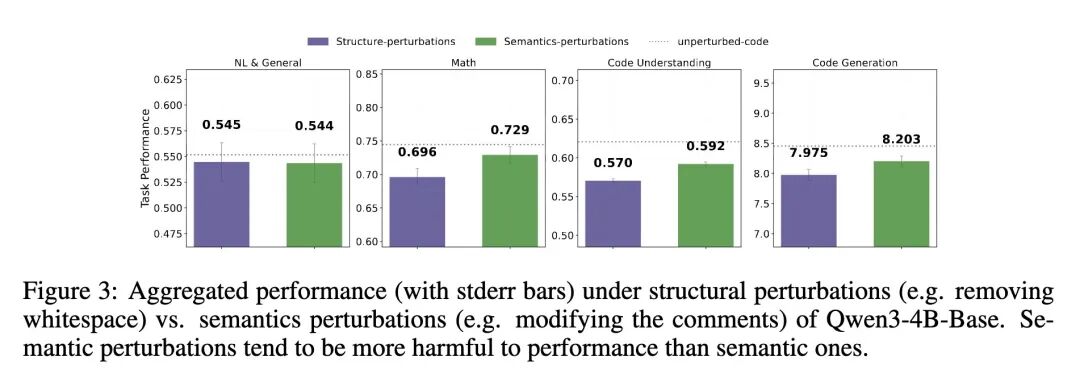
- 最重要的发现是:LLM的推理能力对代码结构属性(如空白符、语法框架)的扰动,比对其语义属性(如变量名、注释)的扰动更为脆弱。这种影响在数学和代码相关任务上尤为显著。
- 揭示了恰当的抽象表示可以与真实代码同样有效,甚至更优。像伪代码和流程图这样用更少token保留算法逻辑的表示形式,往往能维持甚至提升推理性能。
- 一个高度反直觉的发现:即使在含有误导性语义信号(如内容错误的注释、无意义的关键词)的损坏代码上进行微调,只要代码表面的结构规律得以保留,模型依然能保持惊人的竞争力。
- 证明了不同编程语言的句法风格会影响特定任务的增益:Python的语法更有利于自然语言推理,而像Java和Rust这样更低级、更冗长的语言则为数学推理提供了更强的信号。
- 展示了信息密度的重要性,但并非“越多越好”。像伪代码这样token数量更少的变体,其表现通常与原始的冗长代码相当甚至更好,表明对核心逻辑的高效编码是关键。
主旨:通过一个大规模、系统性的实验框架,深入剖析并解构代码数据之所以能提升大语言模型推理能力的根本原因,旨在精确识别出代码的结构、语义、抽象层次和语言风格等不同属性在其中扮演的角色及其重要性,从而为优化模型训练数据以增强推理能力提供科学指导。
创新:
- 系统性的实验框架:首次构建了一个集“跨语言并行数据生成”、“系统性可控扰动”和“跨模型家族、跨规模大规模评估”于一体的综合性研究框架,实现了对代码各属性影响的有效解耦。
- 受控扰动的设计:设计了一套全面且精巧的扰动策略,分为基于规则(如移除空白、替换关键词)和基于生成模型(如生成伪代码、流程图、误导性注释)两大类,能够精准地破坏或改变代码的特定属性而不影响其他。
- 并行数据的构建:通过GPT-4o-mini在10种主流编程语言中生成并行的代码指令数据集,确保了在比较不同语言风格时,指令的底层逻辑和意图保持一致,极大地增强了实验的控制性和结论的可靠性。
贡献:
- 核心理论贡献:为“代码提升LLM推理”这一现象提供了强有力的实证解释——结构比语义更重要。这一结论澄清了学术界的长期假设,将研究焦点引向代码的内在逻辑框架。
- 实践指导贡献:研究结果为AI训练数据的设计和选择提供了极具价值的实践指导。例如,不必拘泥于可执行的、完美的源代码,使用更高效的抽象表示(如伪代码)可能达到同样甚至更好的效果,并且更节省token。同时,可以根据目标任务(如数学或自然语言)来选择特定风格的编程语言数据。
- 反直觉的发现:揭示了模型对语义噪声的惊人鲁棒性,即使在注释错误、变量名无意义的情况下,只要结构存在,模型仍能学习推理。这挑战了我们对数据质量的传统认知,并启发了对LLM学习机制的新思考。
提升: 本文是一项分析性研究,其“提升”主要体现在对领域认知的深化上,而非提出新模型刷新性能榜单。
- 推理能力的理解深度:将“代码有益于推理”的模糊认知,提升到了“代码的结构属性是推理能力的关键驱动力,且不同语言风格适用于不同推理任务”的精确认知。
- 训练数据设计的效率:研究表明,可以使用token效率更高的抽象表示(如伪代码)来替代完整代码,这可能在保持甚至提升推理性能的同时,大幅降低训练的计算成本和数据存储成本。
- 模型鲁棒性的认知:通过扰动实验,提升了对LLM在面对数据噪声和损坏时学习能力的理解,特别是其对结构规律的强大捕捉能力。
不足:
- 模型规模的局限性:受资源限制,实验中使用的模型最大为8B参数。这些发现在更大规模(如70B以上)的甚至前沿闭源模型上是否仍然成立,尚待验证。更大模型可能对结构破坏有更强的鲁棒性。
- 扰动和评估的全面性:尽管扰动设计非常全面,但仍未覆盖所有可能的代码属性,如算法复杂度、数据结构多样性等。此外,代码生成任务采用LLM-as-Judge进行评估,虽有其合理性,但相比基于执行的评估方法仍存在潜在偏差。
- 研究范围集中于微调:本研究主要关注指令微调阶段。代码数据在预训练阶段的影响可能更为深远和根本,其动态可能与微调阶段有所不同。
心得:
- 结构是推理的“语法”:本文最深刻的启示是,LLM从代码中学到的不仅仅是解决问题的方法,更重要的是学会了推理的“形式”或“语法”。代码的严谨结构、嵌套逻辑和控制流为模型提供了一个强大的思维脚手架,模型可以将这种结构化的“思维模式”泛化到自然语言等其他领域。内容(语义)可以变化,但形式(结构)是可迁移的。
- LLM是卓越的“模式识别器”,而非“语义理解者”:模型在面对语义被严重破坏但结构得以保留的代码时依然表现出色,这一反直觉的发现极具启发性。它表明LLM可能在更浅的层次上运作,通过捕捉高阶的、抽象的统计规律和结构模式来“推理”,而不是像人类一样进行深度的语义理解。即使注释在胡言乱语,只要
if-else和for循环的“形状”还在,模型就能正常学习。 - 数据设计的“奥卡姆剃刀”原则:研究证明,更简洁、更抽象的表示(如伪代码)可以和复杂的源代码一样有效。这提示我们,在设计训练数据时,应遵循“奥卡姆剃刀”原则——如无必要,勿增实体。关键在于能否以最精炼的形式传达核心的逻辑结构,而不是堆砌冗余的信息。这对于构建高效、经济的AI训练流程至关重要。
一句话总结: 通过一项涵盖3000多次实验的大规模系统性研究,本文得出结论:代码之所以能提升大语言模型的推理能力,关键在于其结构属性而非语义内容,同时反直觉地发现,伪代码等抽象表示同样有效,且模型对语义层面的严重破坏具有惊人的鲁棒性,只要结构模式得以保留。
Code data has been shown to enhance the reasoning capabilities of large language models (LLMs), but it remains unclear which aspects of code are most responsible. We investigate this question with a systematic, data-centric framework. We construct parallel instruction datasets in ten programming languages and apply controlled perturbations that selectively disrupt structural or semantic properties of code. We then finetune LLMs from five model families and eight scales on each variant and evaluate their performance on natural language, math, and code tasks. Across 3,331 experiments, our results show that LLMs are more vulnerable to structural perturbations than semantic ones, particularly on math and code tasks. Appropriate abstractions like pseudocode and flowcharts can be as effective as code, while encoding the same information with fewer tokens without adhering to original syntax can often retain or even improve performance. Remarkably, even corrupted code with misleading signals remains competitive when surface-level regularities persist. Finally, syntactic styles also shape task-specific gains with Python favoring natural language reasoning and lower-level languages such as Java and Rust favoring math. Through our systematic framework, we aim to provide insight into how different properties of code influence reasoning and inform the design of training data for enhancing LLM reasoning capabilities.
https://arxiv.org/abs/2509.21499
5、[CL] Dual-Head Reasoning Distillation: Improving Classifier Accuracy with Train-Time-Only Reasoning
J Xu, D Zhou, V Shukla, Y Yang...
[Google]
双头推理蒸馏:用仅训练时推理提高分类器精度
要点:
- 解决了思维链(CoT)提示在提升准确率的同时,会带来巨大推理吞吐量损失这一关键权衡问题。
- 提出了一种名为“双头推理蒸馏”(DHRD)的训练方法,该方法对于仅解码器(decoder-only)语言模型而言,简单而高效。
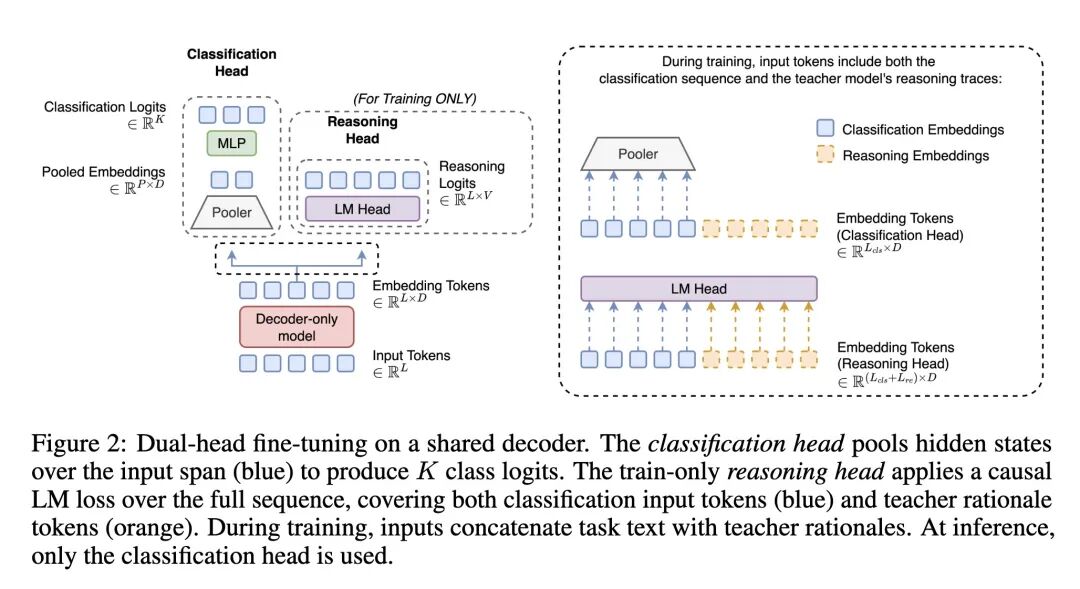
- DHRD架构在共享的骨干网络上设计了两个“头”:(i)一个标准的池化分类头,用于训练和推理;(ii)一个推理(语言模型)头,仅在训练阶段使用。
- 训练过程中,模型使用一个联合损失函数进行优化:该函数是标准分类交叉熵损失与一个辅助性语言模型损失的加权和,其中语言模型损失作用于包含了教师模型生成的推理过程的序列。
- 在推理阶段,推理头被完全停用。模型作为一个标准的、快速的池化分类器运行,不生成任何推理过程。
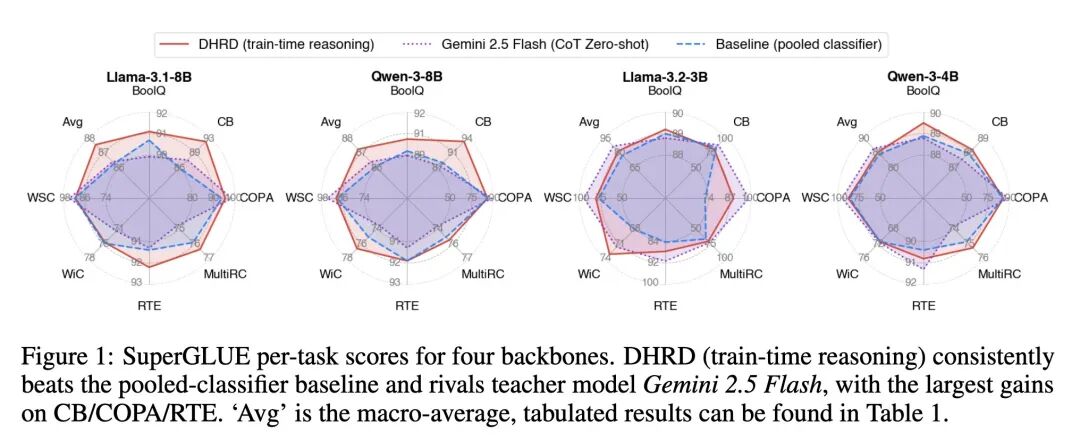
- 在七个SuperGLUE任务上,DHRD相比于基线池化分类器取得了0.65–5.47%的相对准确率提升,其中在蕴含和因果推理类任务(如CB, COPA, RTE)上提升尤为显著。
- 该方法效率极高,推理速度与标准池化分类器持平,在相同模型架构下,其每秒查询数(QPS)比CoT解码方式快了惊人的96–142倍。
- 消融实验揭示了一个关键且反直觉的洞见:性能的提升并非源于通用的语言模型正则化,而是关键依赖于模型学习输入-推理过程-标签三元组之间的对齐关系。在训练中有意地使用不匹配的推理过程会导致性能急剧下降。
- 经过训练的学生模型(例如8B参数模型)在SuperGLUE上的平均得分甚至能够超过为其提供推理过程的、具备CoT能力的教师模型(Gemini 2.5 Flash)。
主旨:解决大语言模型在分类任务中,由思维链(CoT)带来的高准确率与高推理延迟之间的矛盾。为此,文章提出了一种名为“双头推理蒸馏”(DHRD)的训练范式,其核心思想是将CoT的推理过程的计算成本完全转移到训练阶段,从而在部署时既能享受到推理带来的准确率提升,又能保持标准分类器的高吞吐量和低延迟。
创新:
- 训练与推理的解耦:最具创新性的思想是“仅在训练时进行推理”。通过在训练时引入一个专用的推理头和辅助损失,将推理能力“蒸馏”或“烘焙”进模型的参数中,而在推理时则完全舍弃这个过程,实现了推理能力与推理行为的解耦。
- 双头架构设计:针对仅解码器模型,巧妙地设计了“分类头+推理头”的双头架构。分类头负责高效的最终预测,而推理头则作为一种训练时的“脚手架”,引导模型学习更深层次的语义和逻辑关系,训练结束后即可丢弃。
- 对齐学习机制的验证:通过精巧的消融实验,首次明确证实了这类方法的成功关键在于学习“输入-推理-标签”三者之间的强对齐关系,而非简单的语言模型正则化,为理解“为什么推理蒸馏有效”提供了坚实的证据。
贡献:
- 方法贡献:提出了一种简单、通用且高效的DHRD训练方法,为在资源受限或高吞吐量场景下提升模型推理能力提供了一个极具实践价值的解决方案。
- 实证贡献:在多个标准数据集和模型上,用充分的实验数据证明了DHRD在准确率和效率上的双重优势,特别是量化了其相对于CoT解码高达两个数量级的速度提升。
- 理论贡献:通过消融实验,为“推理蒸馏”类方法提供了机制层面的解释,阐明了对齐学习在其中的核心作用,加深了社区对如何将过程知识(如何推理)转化为模型隐式能力(更准确的预测)的理解。
提升:
- 准确率:在7个SuperGLUE任务上,宏平均分相比基线模型有0.65%至5.47%的相对提升。在推理密集型任务上提升更为显著,例如在COPA任务上对Llama-3.2-3B模型的准确率提升高达23.5%。
- 推理效率:推理吞吐量(QPS)与高效的基线池化分类器完全相同,同时比在同一模型上进行CoT解码快了96到142倍。这极大地降低了部署具有强推理能力的模型的成本和延迟。
不足:
- 依赖高质量的教师推理:该方法的有效性高度依赖于教师模型生成的高质量且与标签一致的推理过程。如果教师模型的推理有误或质量低下,可能会损害甚至降低学生模型的性能。
- 超参数敏感性:模型的最终性能对联合损失函数中的权重超参数(α 和 β)较为敏感。例如,对于4B规模的模型,过大的语言模型损失权重(α)反而会损害性能,需要针对不同模型进行调整。
- 评估范围有限:实验主要集中在SuperGLUE的英文分类任务和3B-8B规模的模型上。该方法在其他语言、模态、任务类型(如生成任务)和更大模型规模上的泛化能力尚待验证。
- 单次运行实验:由于计算资源限制,所有实验均为单次运行,未提供置信区间,这在一定程度上影响了结果的统计稳健性。
心得:
- 推理能力可以被“编译”而非“解释”:本文最深刻的启发是,模型的推理能力不一定需要在推理时以一步步生成文本的“解释”形式展现,而是可以被“编译”或“烘焙”到模型的参数权重中。模型在训练中学会了如何推理,这种学习改变了它的内部表征,使其在推理时能做出更准确的“直觉”判断,而无需“展示计算过程”。
- 对齐是比知识本身更强的学习信号:消融实验的结果极具洞察力。仅仅让模型多接触一些语言知识(即使是相关的推理文本)是不够的,真正驱动学习的是任务、推理过程和正确答案三者之间的强对齐关系。一个随机的、不匹配的推理过程甚至比没有推理过程更有害。这凸显了高质量、结构化的“过程数据”在教授模型复杂技能时的核心价值。
- 高效与可解释性的分离部署策略:DHRD为解决LLM应用中的一个核心矛盾(效率 vs. 可解释性)提供了一种务实的工程思路。我们可以在昂贵的、离线的训练阶段利用显式的推理过程来构建一个更强大的模型,然后在需要快速响应的生产环境中部署一个高效的、隐式的模型。这启发了一种未来可能的工作模式:为开发审计和生产部署创建不同形态但能力同源的模型。
一句话总结: 本文提出了一种创新的“双头推理蒸馏”(DHRD)方法,通过在训练时引入一个仅用于学习教师模型推理过程的辅助头,成功地将推理能力“蒸馏”到分类器中,从而在实现与标准分类器相同推理速度(比CoT快96-142倍)的同时,显著提升了模型在推理密集型任务上的准确率。
Chain-of-Thought (CoT) prompting often improves classification accuracy, but it introduces a significant throughput penalty with rationale generation (Wei et al., 2022; Cheng and Van Durme, 2024). To resolve this trade-off, we introduce Dual-Head Reasoning Distillation (DHRD), a simple training method for decoder-only language models (LMs) that adds (i) a pooled classification head used during training and inference and (ii) a reasoning head supervised by teacher rationales used only in training. We train with a loss function that is a weighted sum of label cross-entropy and token-level LM loss over input-plus-rationale sequences. On seven SuperGLUE tasks, DHRD yields relative gains of 0.65-5.47% over pooled baselines, with notably larger gains on entailment/causal tasks. Since we disable the reasoning head at test time, inference throughput matches pooled classifiers and exceeds CoT decoding on the same backbones by 96-142 times in QPS.
https://arxiv.org/abs/2509.21487



 微信二维码
微信二维码