

AI agent(AI 智能体)定义:一个具体的系统或程序,它能够在某个环境中感知、决策并采取行动以完成任务。
Agent AI 定义:一类以智能体为核心范式的人工智能技术或系统框架,关注多模态交互、动态适应能力以及通用智能的实现。
两者的关系:
AI agent 是 Agent AI 的一个子集,可以看作是 Agent AI 中某些具体实现的表现形式。
Agent AI 包括了设计 AI agent 的方法和框架,并探索其更广泛、更通用的潜力。
两者的区别:
层次不同:
AI agent 是具体的“智能体”,关注单一功能或任务。
Agent AI 是关于如何开发和改进智能体的科学与技术领域。
目标不同:
AI agent 侧重执行特定任务的有效性和效率。
Agent AI 聚焦于智能体的通用化、动态适应性和长期发展。
适用性不同:
AI agent 适用于当前现实中的单任务或多任务系统。
Agent AI 涉及更宏观的研究议题,包括技术伦理、通用智能、以及人机交互的未来方向。
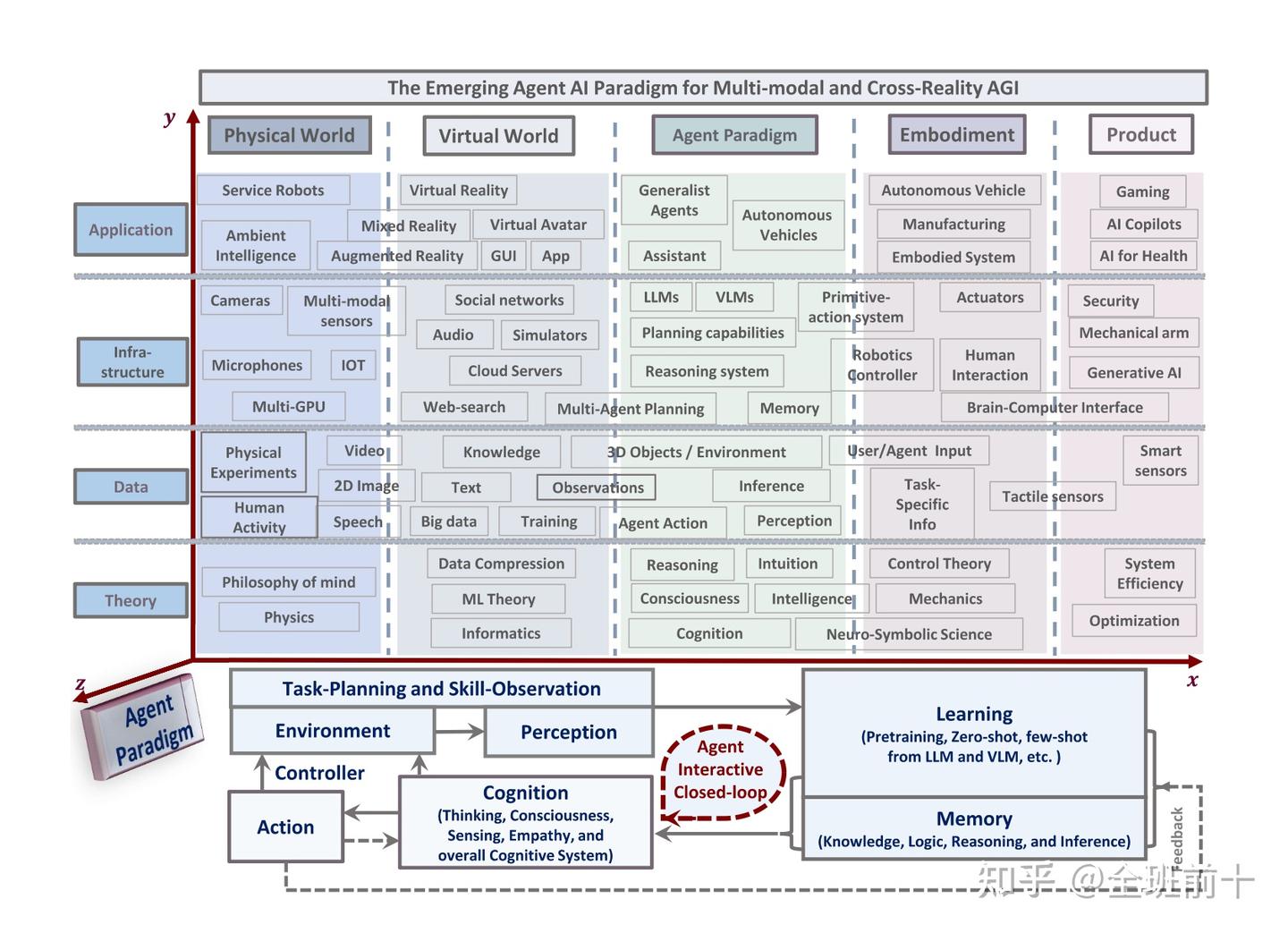
图1:Agent AI 系统概览,该系统能够在不同领域和应用中感知和行动。Agent AI 正逐渐成为通向人工智能(AGI)的一个有前景的方向。Agent AI 的训练展示了其在物理世界中实现多模态理解的能力。它通过结合生成式 AI 和多个独立数据源,Agent AI 提供了一种与现实环境无关的训练框架。通过处理跨现实(物理与虚拟)数据来提升其适应性,增强在物理世界与虚拟环境中行动的能力。我们展示了一个 Agent AI 系统的总体概览,它能够在许多不同的领域和应用中感知并采取行动,可能成为通过代理范式实现 AGI 的路径之一。
多模态人工智能系统可能会成为我们日常生活中无处不在的一部分。想要与这些系统更好交互的一个有前景的方法是将它们作为agent嵌入到物理和虚拟环境中。目前,系统利用现有的基础模型作为构建具身代理体(embodied agents)的基本模块。将代理体嵌入这样的环境中,可以增强模型处理和解释视觉及上下文数据的能力,而这是构建更复杂、更具上下文感知能力的人工智能系统的关键。
例如,一个能够感知用户行为、人类行为、环境对象、音频表达以及场景整体情绪的系统,可以用来在特定环境中引导和调整代理体的响应。为了加速基于代理体的多模态智能的研究,我们将“Agent AI”定义为一类能够感知视觉刺激、语言输入以及其他与环境相关数据的交互式系统,并能够生成有意义的具身行为。特别是,我们探索了通过整合外部知识、多感官输入和人类反馈,提升代理体基于下一步具身动作预测能力的系统。
我们认为,通过在具体环境中开发具身的智能体系统,可以缓解大型基础模型产生幻觉和生成与环境不符的输出的倾向。Agent AI 这一新兴领域涵盖了多模态交互中更广泛的具身化和智能体特性方面(“Agentic aspects”智能体特性方面,这里的“agentic”指智能体具备的特性,包括自主性(autonomy)、目标导向性(goal-oriented behavior)和与环境或其他智能体的交互能力。)。除了代理体在物理世界中的行动和互动,我们还设想了一个未来:人们可以轻松创建任何虚拟现实或模拟场景,并与嵌入虚拟环境中的代理体进行互动。
在历史上,人工智能系统最早在1956年的达特茅斯会议上被定义为能够从环境中收集信息并以有用的方式与其交互的人工生命体。受到这一定义的启发,明斯基(Minsky)领导的麻省理工学院研究小组在1970年开发了一种名为“Copy Demo”的机器人系统,该系统可以观察“积木世界”场景,并成功重建观察到的多面体积木结构。该系统由观察、规划和操控模块组成,揭示了这些独立问题的高难度,并表明进一步研究是必要的。AI领域随后分化为多个专业的子领域,这些领域在解决这些问题以及其他问题方面各自取得了重大进展,但过度简化的做法模糊了AI研究的总体目标。
为了突破现状,有必要回归由亚里士多德整体论(Aristotelian Holism)激发的人工智能基础理论。幸运的是,最近大型语言模型(LLMs)和视觉语言模型(VLMs)的革命,使得创建与整体理念一致的新型 AI 代理体成为可能。抓住这一机遇,本文探讨了整合语言能力、视觉认知、上下文记忆、直觉推理和适应性的模型,并探讨了利用 LLMs 和 VLMs 实现这一整体综合的潜力。在探索过程中,我们还重新审视了基于亚里士多德‘终因’(Final Cause)的系统设计,即‘系统存在的目的’这一目的论理念,这可能在过去的 AI 发展中被忽视了。
随着强大的预训练大型语言模型(LLMs)和视觉语言模型(VLMs)的出现,自然语言处理和计算机视觉领域迎来了复兴。LLMs 现在展现出了卓越的能力,能够解读现实世界中语言数据的细微差别,往往达到了与人类专家相当甚至超越的水平(OpenAI, 2023)。最近的研究表明,LLMs 可以扩展为在不同环境中充当智能体,通过结合领域特定的知识和模块,执行复杂的动作和任务(Xi et al., 2023)。在这些场景中,复杂的推理、智能体对自身角色及环境的理解,以及多步骤的规划能力,均对智能体在环境约束下做出高度细致和复杂决策的能力提出了挑战(Wu et al., 2023;Meta Fundamental AI Research (FAIR) Diplomacy Team et al., 2022)。
在这些初步努力的基础上,人工智能领域正处于一个重要范式转变的边缘,即从为被动、结构化任务创建 AI 模型,向能够在多样化和复杂环境中承担动态、主动角色的模型转变。在这一背景下,本文探讨了将大型语言模型(LLMs)和视觉语言模型(VLMs)作为智能体使用的巨大潜力,重点关注那些融合了语言能力、视觉认知、上下文记忆、直觉推理和适应性的模型。将 LLMs 和 VLMs 用作智能体,尤其是在游戏、机器人和医疗等领域,不仅为最先进的 AI 系统提供了严格的评估平台,还预示着以智能体为核心的 AI 将对社会和各行业产生深远的变革性影响。当这些智能体模型被充分利用时,它们可以重新定义人类体验并提升运营标准。这些模型带来的全面自动化潜力预示着行业和社会经济动态的重大转变。然而,这些进步将不仅涉及技术层面的竞争,还将伴随着复杂的伦理问题,这些内容将在第11节详细阐述。我们在图1中深入探讨了 Agent AI 各个子领域之间的重叠区域,并展示了它们的相互关联性。
接下来,我们将介绍支持 Agent AI 概念、理论背景和现代实现的相关研究论文。
大型基础模型:大型语言模型(LLMs)和视觉语言模型(VLMs)一直是推动通用智能机器开发的核心力量(Bubeck et al., 2023;Mirchandani et al., 2023)。尽管这些模型是通过大规模文本语料库训练的,它们卓越的问题解决能力并不限于传统的语言处理领域。LLMs 具有解决复杂任务的潜力,这些任务曾被认为是人类专家或领域特定算法的专属领域,包括从数学推理(Imani et al., 2023;Wei et al., 2022;Zhu et al., 2022)到回答专业法律问题(Blair-Stanek et al., 2023;Choi et al., 2023;Nay, 2022)。近期研究表明,LLMs 还可以用于为机器人和游戏 AI 生成复杂计划(Liang et al., 2022;Wang et al., 2023a,b;Yao et al., 2023a;Huang et al., 2023a),这是 LLMs 作为通用智能体迈出的重要里程碑。
具身 AI(Embodied AI):许多研究利用大型语言模型(LLMs)执行任务规划(Huang et al., 2022a;Wang et al., 2023b;Yao et al., 2023a;Li et al., 2023a),特别是利用 LLMs 的全球知识(WWW-scale domain knowledge)和新兴的零样本(zero-shot)具身能力,完成复杂的任务规划与推理。近期的机器人研究也通过 LLMs 执行任务规划(Ahn et al., 2022a;Huang et al., 2022b;Liang et al., 2022),方法是将自然语言指令分解为一系列子任务,这些子任务可以以自然语言形式或 Python 代码表示,然后由低级控制器执行这些子任务。此外,这些研究结合环境反馈来提升任务执行性能(Huang et al., 2022b;Liang et al., 2022;Wang et al., 2023a;Ikeuchi et al., 2023)。
交互式学习:用于交互式学习的 AI 智能体,结合了机器学习技术和用户交互,通过用户交互反馈让模型进一步学习。初始阶段,AI 智能体基于大型数据集进行训练。根据智能体的设计初衷,该数据集包含各种类型的信息。例如,用于语言任务的 AI 会训练于大规模文本语料库。训练过程采用机器学习算法,例如深度学习模型(如神经网络),这些模型使 AI 能够识别模式、进行预测,并基于所训练的数据生成响应。此外,AI 智能体还可以从与用户的实时交互中学习。这种交互式学习可以通过多种方式进行:
1)基于反馈的学习:AI 根据用户的直接反馈调整其响应(Li et al., 2023b;Yu et al., 2023a;Parakh et al., 2023;Zha et al., 2023;Wake et al., 2023a,b,c)。例如,如果用户纠正了 AI 的响应,AI 可以利用这些信息改进未来的响应(Zha et al., 2023;Liu et al., 2023a)。
2)观察学习:AI 通过观察用户交互进行隐形学习。例如,如果用户经常提出类似的问题或以特定方式与 AI 互动,AI 可能会调整其响应以更好地适应这些模式。这种方式使 AI 智能体能够理解并处理人类语言、多模态环境,解释跨现实情境并生成适合用户的内容。
随着更多的用户交互和反馈积累,AI 智能体的性能通常会持续提升。这一过程通常由人类操作员或开发人员监督,以确保 AI 学习适当,不会形成偏差或错误模式。
多模态智能体 AI(Multimodal Agent AI, MAA)是一类系统,能够基于多模态感官输入的理解,在特定环境中生成有效的动作。随着大型语言模型(LLMs)和视觉语言模型(VLMs)的兴起,许多 MAA 系统被提出,应用领域涵盖基础研究到实际应用。这些研究领域通过与传统技术的融合(如视觉问答、视觉语言导航)快速发展,同时在数据收集、基准测试和伦理视角等方面存在共同关注点。本文聚焦于 MAA 的一些代表性研究领域,包括多模态性、游戏(VR/AR/MR)、机器人学和医疗保健,旨在提供这些领域共同关切问题的全面知识。通过研究,我们希望掌握 MAA 的基本原理,并获得进一步推动该领域研究的见解。具体学习目标包括:
MAA 概述:深入剖析其原理及在当代应用中的作用,为研究者提供全面理解其重要性和用途的知识。
方法论:通过案例研究(如游戏、机器人学和医疗保健领域),展示 LLMs 和 VLMs 如何增强 MAA 的能力。
性能评估:指导如何使用相关数据集评估 MAA,着重其有效性和泛化能力。
伦理考量:讨论 Agent AI 的社会影响及伦理标准,强调负责任的开发实践。
新兴趋势与未来方向:分类整理各领域的最新进展,并讨论未来的发展方向。
基于计算的行为与通用智能体(Generalist Agents, GAs)在许多任务中都非常有用。一个 GA 要真正对用户有价值,必须既能与用户进行自然的交互,又能够适应多样的场景和数据类型。我们致力于培育一个充满活力的研究生态系统,并在 Agent AI 社区中建立一种共享的身份感和目标感。
MAA(多模态智能体 AI)具有能够适应多样的场景和数据类型的潜力,包括与人类的输入交互。因此,我们相信,Agent AI 领域能够吸引多元化的研究人员,促进动态的 Agent AI 社区和共同目标的形成。在学术界和工业界知名专家的带领下,我们期望本文能够成为一场互动且富有启发性的学习旅程,其中包含智能体教学、案例研究、任务环节及实验讨论,确保为所有研究人员提供全面且引人入胜的学习体验。
本文旨在提供关于当前 Agent AI 研究领域的一般性和全面性知识。为此,本文的结构如下:
第2节 概述了 Agent AI 如何通过与相关新兴技术(尤其是大规模基础模型)的整合获益。
第3节 描述了我们为训练 Agent AI 提出的全新范式和框架。
第4节 提供了 Agent AI 训练中广泛使用的方法论概览。
第5节 对各种类型的智能体进行了分类和讨论。
第6节 介绍了 Agent AI 在游戏、机器人技术和医疗领域的应用。
第7节 探讨了研究界在开发一种多功能 Agent AI 所做的努力,这种 AI 能够适用于各种模态和领域,并弥合虚拟到现实(sim-to-real)的鸿沟。
第8节 讨论了 Agent AI 的潜力,这种 AI 不仅依赖预训练的基础模型,还能够通过与环境和用户的交互不断学习和自我改进。
第9节 介绍了我们专为多模态 Agent AI 训练设计的新数据集。
第11节 探讨了一个热门话题:AI 智能体的伦理考虑、本文的局限性,以及其社会影响。
基于 LLM 和 VLM 的基础模型(如以往研究提出的)在 Embodied AI(具身人工智能)领域仍表现出一定的局限性,尤其是在理解、生成、编辑以及在未见过的环境或场景中进行交互方面(Huang et al., 2023a; Zeng et al., 2023)。因此,这些限制导致了 AI Agents输出的结果达不到预期效果。
当前以agent为中心的 AI 建模方法主要关注定义明确且直接可访问的数据(通过文本和字符表示的世界状态),并通常利用这些数据进行大规模预训练,学到的知识是独立于场景的,用于各种场景的预测通常达不到预期效果(Xi et al., 2023; Wang et al., 2023c; Gong et al., 2023a; Wu et al., 2023)。
在 Huang 等人的研究(2023a)中,我们通过结合大型基础模型,研究了在知识引导的情况下,在协作和交互式场景生成的任务中,展示了比较好的成果。这些结果表明,基于知识的 LLM 智能体能够提升 2D 和 3D 场景的理解、生成和编辑能力,同时改善人机交互性能(Huang et al., 2023a)。通过集成 Agent AI 框架,大型基础模型能够更深入地理解用户输入,从而形成一个复杂且适应性强的人机交互系统(HCI)。
LLM 和 VLM 的新兴能力在生成式 AI、具身 AI、多模态学习的知识增强、混合现实生成、文本到视觉的编辑、人机交互(应用于 2D/3D 游戏或机器人任务仿真)中展现出了巨大的潜力。Agent AI 在基础模型上的最新进展有望成为释放具身智能体通用智能的关键催化剂。
大规模动作模型或“智能体-视觉-语言模型”(agent-vision-language models)为通用具身系统(如规划、问题解决和复杂环境中的学习)开辟了新的可能性。Agent AI 在元宇宙中的进一步探索,以及其作为通往早期 AGI(通用人工智能)的路线,标志着该领域的重要里程碑。
AI agents 具备根据其训练数据,对输入数据进行理解、推理和反馈的能力。虽然这些能力已相当先进并在不断提升,但需要认识到它们的局限性以及训练数据对其性能的影响。一般来说,AI agent 系统具有以下能力:
1)预测建模(Predictive Modeling):AI agents 可以根据历史数据和趋势预测可能的结果或建议下一步行动。例如,它们可以预测文本的后续内容、回答问题、为机器人规划下一步行动,或解决某个场景中的问题。
2)决策能力(Decision Making):在某些应用中,AI agents 能够基于推断做出决策。通常,Agent的决策以最可能实现指定目标的方法进行决策行动。例如,在推荐系统中,AI agent 可以根据对用户偏好的推测,决定推荐哪些产品或内容。
3)处理模糊性(Handling Ambiguity):AI agents 通常可以通过上下文和训练,推断出模糊输入的最可能解释。然而,这种能力受限于其训练数据和算法的范围。
4)持续改进(Continuous Improvement):虽然一些 AI agents 能够从新数据和交互中学习,但大多数大语言模型在训练后不会持续更新其知识库或内部表征。它们的推断通常仅基于训练完成时的数据。
我们在图2中展示了增强型交互式agent,它能够进行多模态,以及跨现实的处理,并具有一种新兴机制。AI agent需要为每个新任务收集大量的训练数据,而这在许多领域可能成本高昂或难以实现。在本研究中,我们开发了一种“无限代理”(infinite agent),它能够从通用基础模型(例如 GPT-X、DALL-E)中学习并将记忆信息迁移到新领域或场景中,用于物理或虚拟世界中的场景理解、生成和交互式编辑。
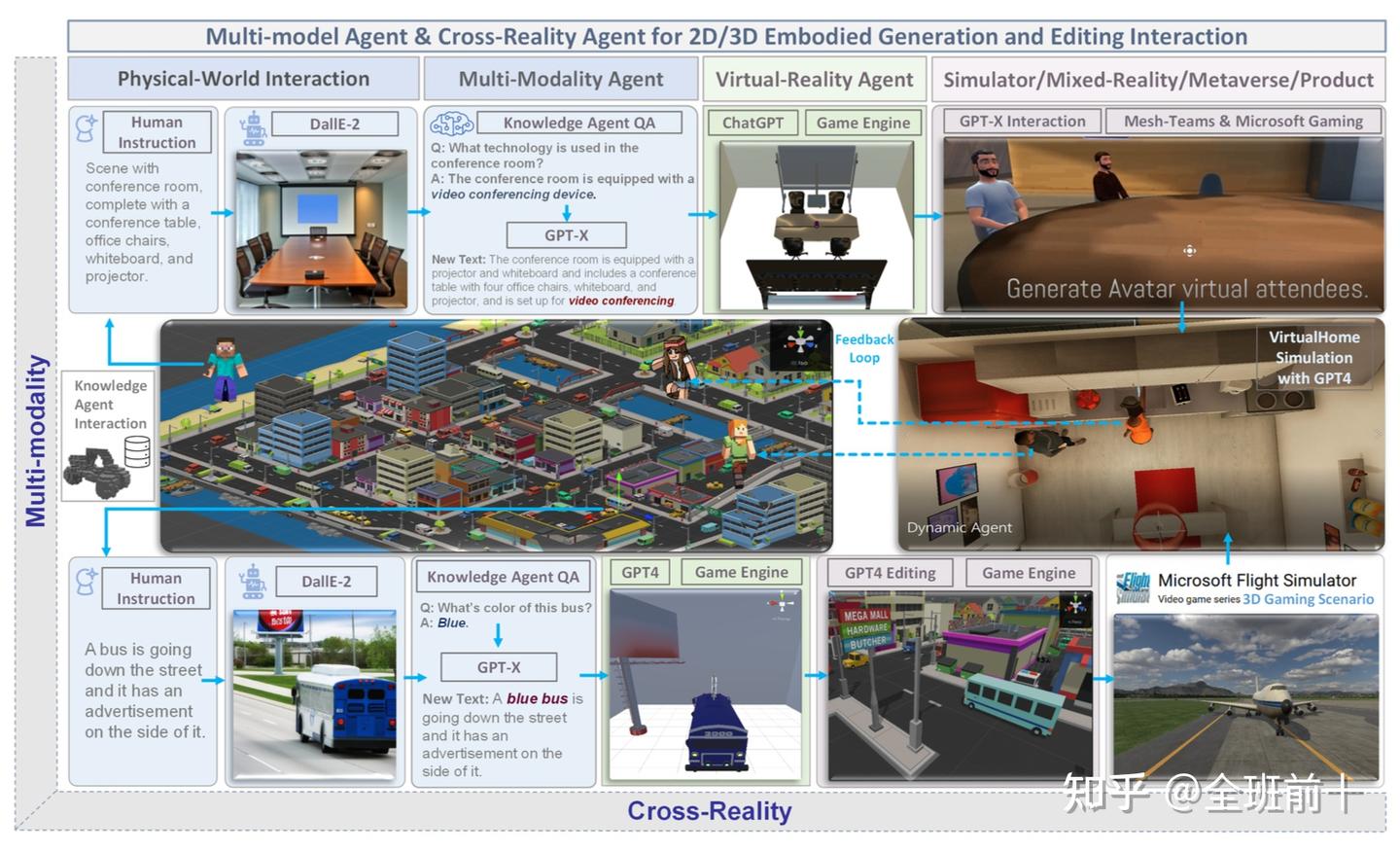
Figure 2: The multi-model agent AI for 2D/3D embodied generation and editing interaction in cross-reality.
这种“无限代理”在机器人领域的一个应用是 RoboGen(Wang et al., 2023d)。在这项研究中,作者提出了一种能够自主运行任务提出、环境生成和技能学习循环的流程。RoboGen 旨在将嵌入于大型模型中的知识迁移到机器人领域。
最近的研究表明,大型基础模型在生成数据方面发挥了关键作用,这些数据可作为基准,用于确定agents在特定环境下的动作。例如,基础模型已被用于机器人操作(Black 等人,2023;Ko等人,2023)和导航任务(Shah 等人,2023a;Zhou 等人,2023a)。
举例说明:
Black 等人 使用图像编辑模型作为高级规划器,生成未来子目标的图像,从而指导低级策略(Black 等人,2023)。
Shah 等人 提出了一种系统,该系统利用大型语言模型(LLM)从文本中识别地标,同时使用视觉语言模型(VLM)将这些地标与视觉输入关联起来,借助自然语言指令提高机器人导航性能(Shah 等人,2023a)。
对于生成受语言和环境因素影响的人类动作,研究兴趣日益增长。一些人工智能系统被提出,用于生成针对特定语言指令而定制的动作和行为(Kim 等人,2023;Zhang 等人,2022;Tevet 等人,2022),并适应各种 3D 场景(Wang 等人,2022a)。这一研究领域强调了生成模型在提升 AI agent在不同场景中的适应性和响应能力方面的潜力。
2.2.1 Hallucinations(幻觉现象)
生成文本的智能体通常容易出现幻觉(hallucinations)现象,即生成的文本可能是无意义的,或与提供的源内容不一致(Raunak 等人,2021;Maynez 等人,2020)。幻觉可以分为两类:内在幻觉 和 外在幻觉(Ji 等人,2023)。
内在幻觉:指生成的内容与源材料相矛盾。
外在幻觉:指生成的文本包含源材料中没有的额外信息。
减少语言生成中幻觉发生率的一些有希望的途径包括使用检索增强生成(Retrieval-Augmented Generation,RAG)(Lewis 等人,2020;Shuster 等人,2021)或其他通过外部知识检索对自然语言输出进行语义支撑(grounding)的方法(Dziri 等人,2021;Peng 等人,2023)。一般来说,这些方法旨在通过检索额外的知识来增强语言生成,同时提供机制来检查生成的结果与知识之间是否存在矛盾。
在多模态智能体系统(multi-modal agent systems)的背景下,视觉语言模型(VLMs)也会出现幻觉现象(Zhou 等人,2023b)。视觉语言生成中幻觉的一个常见原因是模型在训练数据中过度依赖物体与视觉线索的共现关系(Rohrbach 等人,2018)。那些仅依赖预训练的大语言模型(LLMs)或视觉语言模型(VLMs),并且在特定环境中使用有限的微调(fine-tuning)的 AI agent,更容易产生幻觉。这是因为这些智能体依赖预训练模型的内部知识库生成动作,可能无法准确理解其当前环境中各种状态的动态变化。
2.2.2 Biases and Inclusivity(偏见与包容性)
基于大型语言模型(LLMs)或大型多模态模型(LMMs)的 AI agent在设计和训练过程中存在固有的偏见。在设计这些 AI agent时,必须要谨慎考虑包容性,并关注所有终端用户和利益相关者的需求。在 AI agent的背景下,包容性指的是采取措施和原则,以确保智能体的交互反馈具备包容性、尊重性,并对来自不同背景的用户谨慎对待和理解。以下是智能体偏见和包容性的关键方面:
训练数据:基础模型在海量的文本数据上进行训练,这些数据来自互联网上的书籍、文章、网站和其他文本来源。这些数据通常反映了人类社会中存在的偏见,模型可能会无意中学习并重现这些偏见。这包括与种族、性别、民族、宗教和其他个人属性相关的刻板印象、偏见和倾向性观点。尤其是通过对互联网数据(通常是英文文本)的训练,模型可能隐含地学习西方发达、受过教育、工业化、富裕和民主(WEIRD)社会的文化规范(Henrich 等人, 2010),因为这些群体在互联网上占据着主导地位。然而,必须认识到,由人类创建的数据集不可能完全没有偏见,因为这些数据集往往反映了最初生成和编写数据时,生产者个人和社会偏见。
历史和文化偏见:AI 模型的训练数据来源于大量不同的内容。因此,训练数据通常包含旧数据(这里指的是非当下时代的数据,并不只是我们学习的历史课数据),以及各种文化的材料。特别注意,旧数据的训练数据可能包含反映某一社会文化规范、态度和偏见,表现为冒犯性或贬低性语言。这可能导致模型延续过时的刻板印象,或者无法完全理解当代的文化变迁和细微差别。
语言和上下文的局限性:语言模型可能难以理解和准确表达语言的细微差别,例如讽刺、幽默或文化参考。这可能导致在某些情境下出现误解或偏见。此外,纯文本无法完整表达口语中的许多方面,导致模型对文本的理解与人类表达之间可能存在脱节。
政策和准则:AI agent在严格的政策和准则下运行,以确保公平性和包容性。例如,在生成图像时,规则要求对人群的描绘进行多样化,避免与种族、性别等属性相关的刻板印象。
过度泛化:这些模型倾向于根据训练数据中学习到的内容进行回复。这可能导致过度泛化,模型可能产生看似刻板印象,或对某些群体做出宽泛假设的回复。
持续监测与更新:AI 系统会被持续监测和更新,以解决新出现的偏见或包容性问题。用户的反馈和 AI 道德领域的持续研究在这一过程中发挥着至关重要的作用。
主流观点的放大:由于训练数据通常包含来自主流文化或群体的内容较多,模型可能更偏向于这些视角,从而可能忽视或误解少数群体的观点。
道德与包容性设计:AI 工具应以道德考量和包容性为核心原则进行设计。这包括尊重文化差异、促进多样性,并确保 AI 不会使有害的刻板印象长期存在。
用户准则:引导用户以促进包容性和尊重的方式与AI互动。这包括避免提出可能导致偏见或不当的请求。此外,这还能帮助减少模型从用户互动中学习到有害内容的风险。
尽管采取了这些措施,AI agent仍然表现出偏见。目前,智能体 AI 研究和开发的持续努力集中于进一步减少偏见,并增强系统的包容性和公平性。减少偏见的措施:
多元且包容性的训练数据:努力确保训练数据包含更广泛、多样化且具有包容性的来源。
偏见检测与修正:持续的研究致力于检测并修正模型回复中的偏见。
道德准则与政策:模型通常遵循道德准则和政策,旨在减少偏见,确保互动尊重且具包容性。
多样化的代表性:确保 AI agent生成的内容或回复,能代表人类经历、文化、种族和身份的广泛范围。在图像生成或叙述构建等情境中,这尤为重要。
偏见缓解:积极减少 AI 回应中的偏见,包括与种族、性别、年龄、残障、性取向等个人特征相关的偏见。目标是提供公平且不延续刻板印象或偏见的回复。
文化敏感性:AI 旨在具备文化敏感性,认可并尊重不同文化的规范、习俗和价值观。这包括理解文化相关的内容和细微差别,并作出恰当的回应。
可访问性:确保 AI agent对不同能力的用户(包括残障人士)都具有可访问性。这可能包括提供帮助视力、听力、行动或认知受限用户的功能。
基于语言的包容性:支持多种语言和方言,以满足全球用户的需求,并对语言内的细微差别和变化保持敏感(Liu 等人, 2023b)。
道德且尊重的互动:该agent被设计为与所有用户进行道德且尊重的互动,避免产生可能被视为冒犯、有害或不尊重的回应。
用户反馈与适应:结合用户反馈不断改进 AI agent的包容性和有效性。这包括从互动中学习,更好地理解并服务多元化的用户群体。
遵循包容性准则:遵守行业组织、伦理委员会或监管机构设定的包容性准则和标准。
尽管这些努力已付诸实践,仍需意识到 AI 回应中可能存在偏见,并以批判性思维进行解读。AI agent技术和伦理实践的持续改进旨在逐步减少这些偏见。智能体 AI 在包容性方面的首要目标之一是创建一个尊重并适用于所有用户的智能体,无论用户的背景或身份如何。

 微信二维码
微信二维码